Fast enough to empower humans to take action

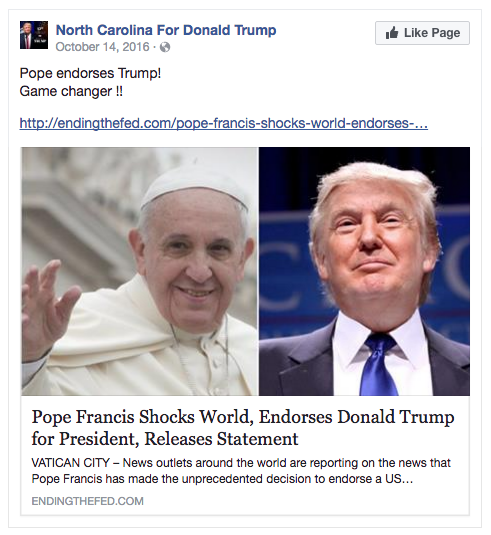
Last November, a friend told me about his extended family of Filipino-Americans in the Fresno area. In a matter of days they went from feeling conflicted about Trump’s candidacy to voting for him en masse. They are Catholics, and once they heard the Pope had endorsed Trump their minds were made up. Of course, this papal endorsement did not really happen. This is an example of fake news wave that went viral and misled millions.
Here is that same story in a Facebook post, shared by the group North Carolina For Donald Trump. They have 65,000 followers, and you can see how shares by dozens of influential groups could spread this to millions.
On the same lines, a site called winningdemocrats.com published a hoax that Ireland is officially accepting “Trump refugees,” which too got a lot of play. This is a bipartisan problem. Journalism is hard work. Fake news for influence and profit is all too easy. Here are more examples.
This made me wonder what Facebook and other platforms could have done to detect these waves of misinformation in real-time. Could they have run countermeasures? If detected in time could they have slowed the spread or marked it as unreliable news?
Platforms need to act
As many have noted, addressing fake news is best done at the level of the major platforms — Facebook, Twitter, Google, Microsoft, Yahoo and Apple. They control the arteries through which most of the world’s fresh information and influence flows. They are best positioned to see a disinformation outbreak forming. Their engineering teams have the technical chops to detect it and the knobs needed to to respond to it.
Both social networks and search engines have engineering levers (think: ranking flexibility) and product options to reduce exposure, mark as false, or fully stop misinformation waves. They will make these decisions individually based on the severity of the problem and how their organization balances information accuracy and author freedom. Google Search has a focus on information access. Facebook sees itself as a facilitator of expression. They may resolve things differently.
Our approach will focus less on banning misinformation, and more on surfacing additional perspectives and information, including that fact checkers dispute an item’s accuracy. — Mark Zuckerberg
In this article I prefer not to get into policy, and would like to focus on detection rather than advocating a specific response. No matter what your response, if you can detect fake news in real-time you can do something about it.
Real-time detection, in this context, does not mean seconds. It may be unnecessary to take action if it does not spread. In practice, rapid response could mean minutes or hours. Time enough for an algorithm to detect a wave of news that seems suspicious and is gathering momentum, potentially from multiple sources. Also, enough of a window to gather evidence and have it considered by humans who may choose to arrest the wave before it turns into a tsunami.
I know a thing or two about algorithms processing news. I built Google News and ran it for many years. It is my belief that detection is tractable.
I also know that it is probably not a good idea to run anything other than short-term countermeasures solely based on what the algorithm says. It is important to get humans in the loop — both for corporate accountability and to serve as a sanity check. In particular, a human arbiter would be able to do proactive fact checking. In the above example, the Facebook or Twitter representative could have called the press office of the Holy See and established that the story is false. If there is no obvious person to call they could check with top news sources and fact checking sites to get their read on the situation.
There will ambiguous cases and situations where verification is elusive. The human arbiters may decide to wait and monitor the wave for a while before they intervene. Over time a machine learning system could learn from the outcome, start to use more evidence, and train itself to become smarter.
What is a wave? A wave in my parlance is a set of articles that make the same new (and possibly erroneous) claim, plus associated social media posts. A wave is significant if it is growing in engagement. Since the cost of human intervention is high, it only makes sense to flag significant waves that have traits that suggest misinformation.
The goal of the detection algorithm is to flag suspicious waves before they cross an exposure threshold, so that human responders can do something about it.
To make this concrete: Let us say that a social media platform has decided that it wants to fully address fake news by the time it gets 10,000 shares. To achieve this they may want to have the wave flagged at 1,000 shares, so that human evaluators have time to study it and respond. For search, you would count queries and clicks rather than shares and the thresholds could be higher, but the overall logic is the same.
Algorithmic Detection
To detect anomalous behavior we have to look below the surface and see what’s not happening. This, from a Sherlock Holmes story captures the essence of our strategy.
Gregory (Scotland Yard detective): “Is there any other point to which you would wish to draw my attention?
Sherlock Holmes: “To the curious incident of the dog in the night-time.”
Gregory: “The dog did nothing in the night-time.”
Sherlock Holmes: “That was the curious incident.”
— The Adventure of Silver Blaze, Arthur Conan Doyle
What makes detecting fake news tractable is that platforms are able to observe articles and posts, not just in isolation, but in the context of all else that is being said on that subject in real-time. This expanded and timely context makes all the difference.
Let’s take the “Pope endorses Trump” story.
If you are an average Facebook user and the article was shared to you by a friend, you have no reason to disbelieve it. We have a truth bias that makes us want to believe things typeset in the format of a newspaper, especially if it is endorsed by someone you know. Hence, the outgrowth of newly minted fake news sites that are trying to look legitimate. Some by Macedonian teenagers, purely for profit, or by political professionals or foreign actors seeking to influence elections. As they get tagged and put on blacklists new sites are created out of necessity.
A skeptic would ask: How likely is it that endingthefed.com, a relatively obscure source, is one of the first to report a story about the Pope endorsing Trump, while established sources like the New York Times, Washington Post, BBC, Fox News, CNN, etc. and even the Vatican News Service, have nothing to say on the subject? That would seem unnatural. It would be even more suspicious if the set of news sites talking about this are all newly registered or have a history of running fake news. This is the logic we are going to employ, but with some automation.
To do this at scale, an algorithm would look at all recent articles (from known and obscure sources) that have been getting some play in the last 6–12 hours on a particular social network or search engine. To limit the scope we could require a match with some trigger terms (e.g., names of politicians, controversial topics) or news categories (e.g., politics, crime, immigration). This would reduce the set to around 10,000 articles. These articles can be analyzed and grouped into story buckets, based on common traits — significant keywords, dates, quotes, phrases, etc. None of this is technically complex. Computer Scientists have been doing this for decades and call this “document clustering.”
Articles that land in a given story bucket would be talking about the same story. This technique has been used successfully in Google News and Bing News, to group articles by story and to compare publishing activity between stories. If two different sources mention “pope” and “Trump” and some variant of the term “endorsed” within a short time window then their articles will end up in the same bucket. This essentially helps us capture the full coverage of a story, across various news sources. Add in the social context, i.e., the posts that refer to these articles, and you have the full wave. Most importantly this allows us to figure out comprehensively which sources and authors are propagating this news and which are not.
To assess whether the wave needs to be flagged as suspicious, the algorithm will need to look at traits of both the story cluster and the social media cloud surrounding it. Specifically:
- Is the wave on a topic that is politically charged? Does it match a set of hot button keywords that seem to attract partisan dialog?
- Is engagement growing rapidly? How many views or shares per hour?
- Does it contain newly minted sources or sources with domains that have been transferred?
- Are there sources with a history of credible journalism? What’s the ratio of news output to red flags?
- Are there questionable sources in the wave
(a) Sources flagged for fake news by fact checking sites (e.g., Snopes, Politifact)
(b) Sources frequently co-cited on social feeds with known fake news sources.
(c) Sources that bear a resemblance to known providers of fake news in their affiliation, web site structure, DNS record, etc. - Is it being shared by users or featured on forums that have historically forwarded fake news? Are known trolls or conspiracy theorists propagating it?
- Are there credible news sites in the set? As time passes this becomes a powerful signal. A growing story that does not get picked up by credible sources is suspicious.
- Have some of the articles been flagged as false by (credible) users?
Each of the above can be assessed by computers. Not perfectly perhaps, but sufficiently well to serve as a signal. Some carefully constructed logic will combine these signals to produce a final score to rate how suspicious the wave is.
When a wave has the traits of a fake news story the algorithm can flag it for human attention, and potentially put temporary brakes on it. This will buy time and ensure that it does not cross the high water mark of say, 10,000 shares or views, while the evaluation is in progress.
With every wave that is evaluated by human judges — and there may be several dozen a day — the system will get feedback. This in turn allows algorithmic/neural net parameters to be tuned and helps extend the track record for sources, authors and forums. Even waves that could not be stopped in time, but eventually proved to be misinformation, could contribute to improve the model. Over time this should make detection more accurate, reducing the incidence of false alarms in the flagging step.
Free Expression and Abuse
Trading free expression for security is a slippery slope and inevitably a bad idea.
It is important that the policing of fake news by platforms happen in a way that is both defensible and transparent. Defensible, in the sense that they explain what they are policing and how this being executed, and operate in a manner that the public is comfortable with. I would expect them to target fake news narrowly to only encompass factual claims that are demonstrably wrong. They should avoid policing opinion or claims that cannot be checked. Platforms like to avoid controversy and a narrow, crisp definition will keep them out of the woods.
In terms of transparency, I would expect all news that has been identified as false and slowed down or blocked to be revealed publicly. They may choose to delay this to avoid tipping their hand during the news cycle, but they should disclose within a reasonable period (say, 15 days) all news that was impacted. This, above all else, will prevent abuse by the platform. Google, Facebook and others have transparency reports that disclose censorship and surveillance requests by governments and law enforcement. It’s only appropriate that they too are transparent about actions that limit speech.
Having been on the other side of this issue, I can think of reasons why details of the detection algorithm may need to be kept secret. A platform, in an arms race with fake news producers, may find that their strategy stops working if too much is made public. A compromise would be to document details of the implementation and make it available for internal scrutiny by (a panel of) employees. Also, for auditing by an ombudsman or authorized external lawyers. When it comes to encouraging good corporate behavior employees are the first line of defense. They are technically capable and come from across the political spectrum. They can confirm there is no political bias in the implementation.
The biggest challenge to stopping fake news is not technical. It is operational willingness.
The scale and success of our major platforms made this large-scale assault on truth possible in the first place. They are also best positioned to fix it. They can set up sensors, flip levers, and squash fake news by denying it traffic and revenue.
My concern is whether the leadership in these companies recognizes the moral imperative and has the will to take this on at scale, invest the engineering that is needed, and act with the seriousness that it deserves. Not because they are being disingenuous and it benefits their business — I genuinely believe that is not a factor — but because they may think it’s too hard and don’t want to be held responsible for errors and screw-ups. There is no business imperative to do this and there may be accusations of bias or censorship, so why bother?
If they are willing to get beyond that and own the problem — and recent signs suggest they do (e.g, Facebook paying fact checkers, ranking changes at Google) — I believe their users and the press will appreciate it and support them. With transparency and the right response they can do an immense amount of good to society and ensure that democracies operate correctly. The alternative is terrifying.